Ein sauberer Kreislauf zu Apple Health
Jedes Training mit Route und Splits zurück nach Apple Health schreiben, und der Datenverlust-Bug, den ich einen Speichervorgang vor dem Ernstfall erwischt habe.
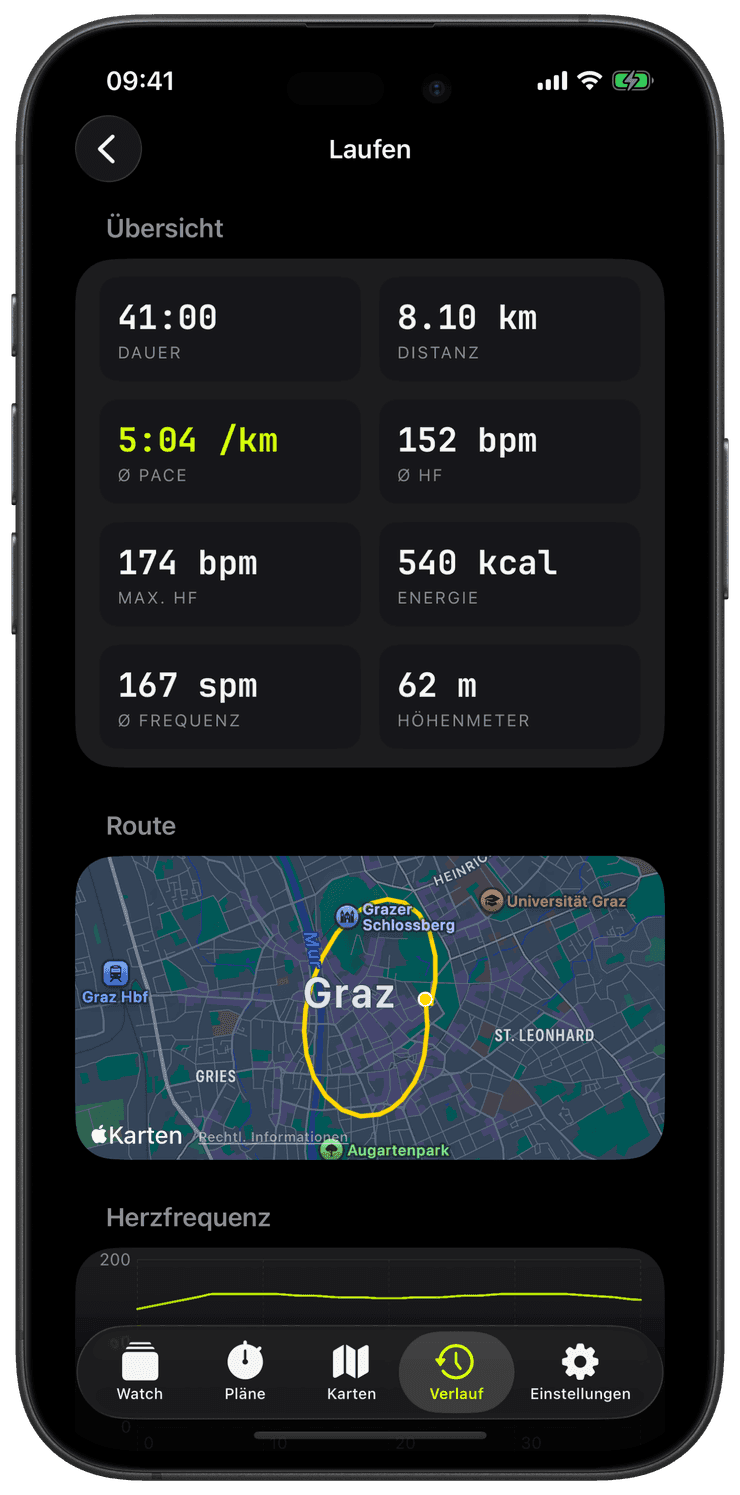
Ein Training, auf das du später nicht zurückblicken kannst, ist nur eine Stoppuhr. In diesem Beitrag geht es um den Kreislauf: jede Einheit ordentlich in Apple Health schreiben, einen Ort bauen, um sie zu durchstöbern, und den Bug, der diese ganze Pipeline beinahe in einen Datenschredder verwandelt hätte.
Vollständig zurückschreiben
Wenn du auf Stopp tippst, schreibt Runara ein vollständiges Training in Apple Health: die Route als echtes Routenobjekt, Herzfrequenzwerte, Distanz, aktive Energie und Segment-Ereignisse, damit auch deine Splits erhalten bleiben. Der Routen-Builder wird im Moment des Trainingsstarts erzeugt und unterwegs mit GPS gefüttert, sodass es am Ende nichts mehr zusammenzubauen gibt, es ist bereits korrekt.
Das ist wichtiger, als es klingt, und es führt direkt zurück zum Warum. Deine Trainings liegen nicht in irgendeiner Runara-Datenbank, die ich kontrolliere. Sie liegen in Apple Health, auf deinem Telefon. Apple Fitness sieht sie. Jede andere Health-fähige App sieht sie. Und wenn du Runara morgen löschst, ist deine Trainingshistorie immer noch da, weil sie nie meine war, um sie als Geisel zu nehmen. Das ist die Datenschutzhaltung konkret gemacht: Die App ist ein guter Gast in deinen Daten, kein Vermieter.
Der Verlauf-Tab ist die andere Hälfte. Er listet jedes gespeicherte Training und öffnet jedes davon zu einer Routenkarte, einer Splits-Tabelle und den Metrik-Diagrammen. Ihn zu bauen brachte eine kleine, aber echte Lästigkeit ans Licht: Apple hat die bequemen Eigenschaften totalDistance und totalEnergyBurned an Trainings für veraltet erklärt, also stellte ich alles auf die neueren Statistik-Abfragen um. Mühsam, aber die Art von Sache, die man einmal repariert und vergisst.
Akku, und Zahlen laut vorlesen
Zwei Stücke Feinschliff landeten hier, die mir unverhältnismäßig wichtig sind.
Das Erste ist der Akku. GPS ist der hungrige Teil jeder Lauf-App, also ist Genauigkeit eine Einstellung, keine feste Kostenstelle. "Beste" gibt dir eine enge Fünf-Meter-Spur und frisst auf einem langen Lauf Akku. "Ausgewogen" und "Energiesparmodus" lockern Genauigkeit und Aktualisierungsabstand für die Tage, an denen du lieber mit Reserve ankommst. Du entscheidest, was der Lauf wert ist.
Das Zweite ist Barrierefreiheit. Die Metrik-Ziffern bekommen ordentliche VoiceOver-Labels, sodass die Watch "fünf Komma zwei Kilometer pro Stunde" sagt, nicht "fünf, Pause, Komma, Pause, zwei". Und die Herzfrequenzzonen erhielten eine optionale farbenblind-sichere Palette, deren Helligkeit von Zone zu Zone stetig steigt, sodass sie korrekt lesbar bleibt, selbst wenn die übliche Rot-zu-Grün-Rampe für deine Augen nicht funktioniert. Ich bin nicht farbenblind, aber ein gutes Instrument sollte für jeden lesbar sein, der es in der Hand hält.
Der Bug, der mir Angst machte
Jetzt der, der mich wirklich durchgerüttelt hat.
Erinnerst du dich an die Regel aus dem ersten Beitrag, die wie Paranoia aussah: Jeder gespeicherte Typ muss es vertragen, zurückgelesen zu werden, wenn die App inzwischen neue Felder bekommen hat. Hier ist, was passiert, wenn man sie vergisst, was ich tat, an genau einer Stelle.
Swifts automatisches Decodieren wirft einen Fehler, wenn einem gespeicherten Wert ein Feld fehlt, selbst ein Feld mit einem Standardwert. Jedes Feature, das ich seit der ersten Version hinzugefügt hatte, GPS-Genauigkeit, die farbenblind-sichere Palette, Intervallpläne, Audio-Hinweise, brach still das Decodieren jedes Einstellungs-Blobs, der vor diesem Feature gespeichert worden war. Und der Fehlermodus war die schlimmste Sorte:
Swift's synthesized Codable.init(from:) throws keyNotFound when a stored property is missing, even when the property has a default. [...] decode() catches the error, returns fresh defaults, UI shows empty, next save overwrites the still-intact on-disk blob with empties, user's data gone.
Lies diese Kette noch einmal, denn sie ist eine Horrorgeschichte in fünf Schritten. Das Decodieren scheitert. Die App zuckt mit den Schultern und lädt leere Standardwerte. Du siehst eine leere App und denkst "hä?". Du änderst eine Einstellung. Dieser Speichervorgang schreibt den leeren Zustand über deine echten, noch tadellosen Daten auf der Platte. Jetzt sind sie tatsächlich weg. Die App löschte deine Einstellungen, und sie tat es höflich, Schritt für Schritt, während sie aussah, als würde sie funktionieren.
Die Lösung:
fix(persistence): UserSettings Codable now tolerates missing keys, ends redeploy data-loss
Handgeschriebenes Decodieren, das jedes neuere Feld als optional mit sinnvollem Standardwert liest. Alte Daten laden sauber. Drei Regressionstests nageln diesen Vertrag jetzt fest, sodass er nie wieder still verrotten kann, und der Catch-Block, der die ganze Kaskade startete, loggt jetzt laut, statt den Fehler zu verschlucken. Außerdem habe ich "jeder gespeicherte Typ folgt dieser Regel" von einer Notiz zu einer harten Projektregel befördert.
Eine verwandte, sanftere Variante desselben Themas zeigte sich beim Onboarding:
fix(onboarding): restore first-run starter screens that landed empty
Frische Installationen begrüßten die Leute mit einem leeren Blatt statt der drei Starter-Screens, die sie bekommen sollten. Dieselbe Problemfamilie, viel niedrigerer Einsatz, aber eine Erinnerung daran, dass "der erste Lauf" und "der tausendste Lauf nach einem Update" beide Grenzfälle sind, die einen Test verdienen.
Der ehrliche Teil
Ich will klar sein über die Aufteilung zwischen Mensch und Maschine, denn genau hier kommt es darauf an. Claude schrieb viel korrekten, sauberen Code sehr schnell. Es sah nicht von selbst voraus, dass ein abgefangener, auf Standardwerte zurückfallender Decodier-Fehler in stillen Datenverlust quer über ein App-Update kaskadieren würde. Das ist eine Sorge auf Systemebene, ein "was passiert auf dem unglücklichen Pfad drei Releases später", und das zu erwischen lag an mir, an meiner Erfahrung, meiner Paranoia, meinem Beharren darauf, den Regressionstest zu schreiben, der beweist, dass es behoben bleibt. Das ist der Teil, den man nicht auslagern kann, und genau der Grund, warum ich es ruhigen Gewissens mit meinem Namen versehe.
Als Nächstes: der Watch das Coachen beibringen, mit strukturierten Intervallen und einer Stimme, die wirklich Deutsch spricht.